Despite the title, this is not a sci-fi post. However, if you are new to data modeling and Power BI, it may seem futuristic to you.
In this post, I will explain the concept of star schema data modeling and it’s related concepts dimension- and fact tables. Setting up a smart star schema design will make your data exploration and dashboard building so much easier. In order to do that, we need to know what fact- and dimension tables are and how they are intended to be used.
What do we mean by fact- and dimension tables?
When I started out with data modeling in Power BI, the hint to make a distinction between dimension and fact tables was exactly the type of hint I discarded as too technical and complicated and not necessary for what I wanted to build. It’s neither of those things. Using a star schema data model is easier from a user perspective, and almost always applicable.
Instead, if I would have invested a few minutes into understanding why a data model is different and (sometimes) better than my Excel spreadsheets, it would have saved me a lot of time down the line.
So let’s start by having common terminology.
A dimension table is a table about something that we want to explore. As an example, a dimension table can tell you about an entity’s place in a hierarchy, group together a handful of entities, or relate a date in a longer timeline.
A fact table contains occurances of the things we want to explore. Each row contains information of a single event or transaction, that is further described in the dimension tables.
The fact table contains information that is unique to the transaction, while the dimension table holds information that is shared and compared.
Take a financial model where we want to track actuals on a P&L based on data from our accounting system. The fact table would contain each transaction made in the accounting system, maybe one row per journal entry. We could perhaps store information on the amount, the currency, the cost/revenue center, the date, the counterpart, and the account of the transaction. All things unique to the transaction.
What’s not unique to the transaction is how an account relates to the CoA hierarchy – which accounts sums up to which P&L-row. Or which counterparts that are preferred suppliers and which that are secondary or worse choices. This type of information is suitable in a dimension table.
Why should I build a star schema?
Increase performance – reduce data
If you only have one fact table, your model could just be one wide (with many columns) table. But this may be a bad idea, despite being a fully functional solution. That’s because using dimensions may drastically reduce the data in your model.
Let’s expand on our P&L-example. Let’s say we have 1000 transactions on 10 different accounts. We can either put the sum-level information in the fact table, or in a related accounts dimension table. If we put the information in the fact table, we need an additional column with information for all transactions. That’s 1000 additional cells of information. Instead, if we have a table with the sum level for each account and relate the fact- and the dimension table on the account key, we only get 10 new rows – one for each account. Consider that your data sets may grow to millions of rows, and you’ll start to understand why smart data modeling is key for dashboard performance.
Avoid many-to-many relationships
If you have multiple fact tables that you somehow want to compare, you need to use dimension tables to avoid many-to-many relations. Power BI allows for many-to-many relations, but it’s clearly stated that if you don’t fully understand how these relationships works, you risk getting erroneous output.
In our finance example above, one may argue that actuals without context is useless. Perhaps you want to compare the actuals to a plan or a budget. This plan is also suited for a fact table, as it contains information across multiple dimensions – maybe a forecasted outcome for an account on a cost center a given month.
If we want to compare actuals to the plan for an account on a cost center, we need to tell Power BI how these relate. If we make a direct relationship between the cost center column in the plan-table and the actual-table, we will get a many-to-many relationship, and likely get outputs in the dashboard that are wrong. But the cost centers in both tables relate to the same cost center hierarchy, where each cost center only occur once. So we can put this hierarchy as a dimension table, and let both fact tables have many-to-one relationships to this dimension table. Then, Power BI knows how the two fact tables relate to each other, and we can add additional information to the dimension table like sum-levels or cost center owners with little additional data.
Suite yourself
Now, the applications and underlying data always varies. These best practice rules may very well be too generalized for your specific problem, so the star schema may not work for you. But you should know the rules and know when you deviate from them.
How do I build a star schema?
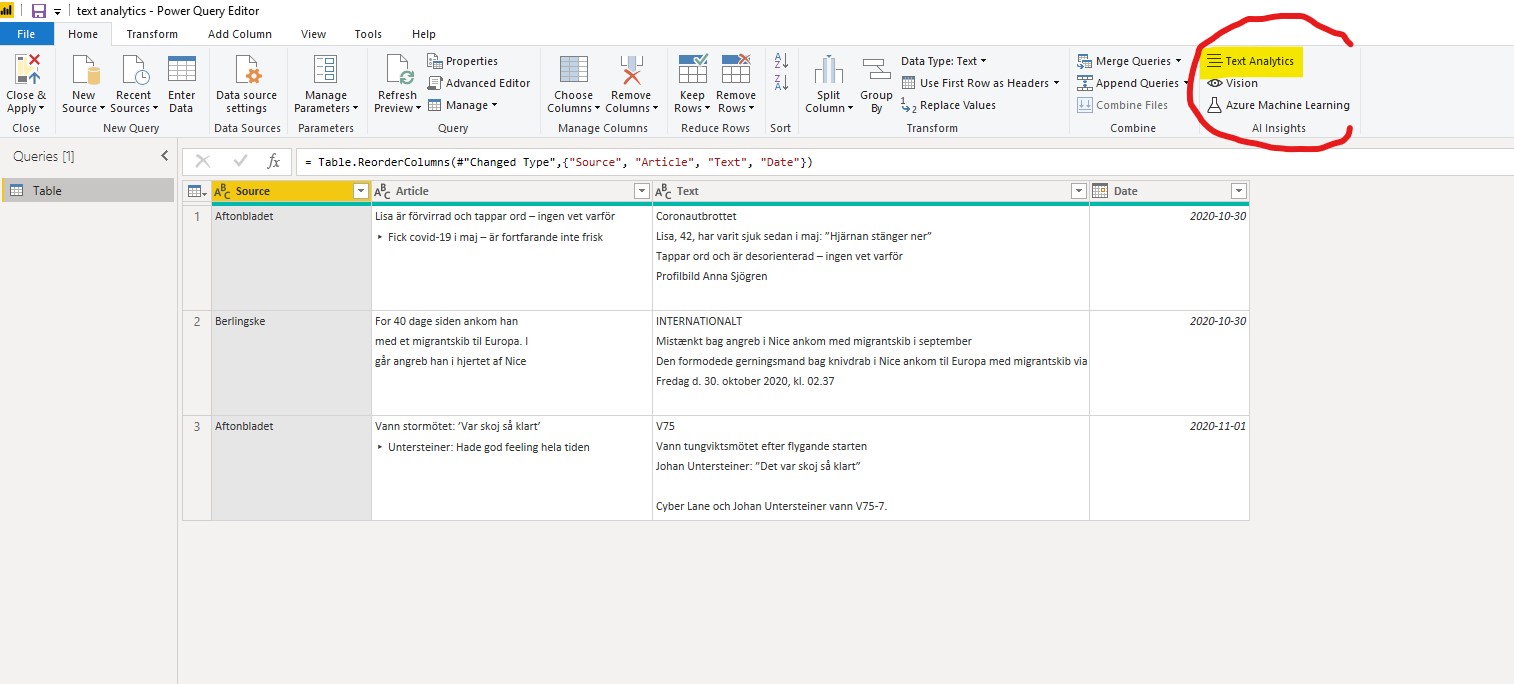
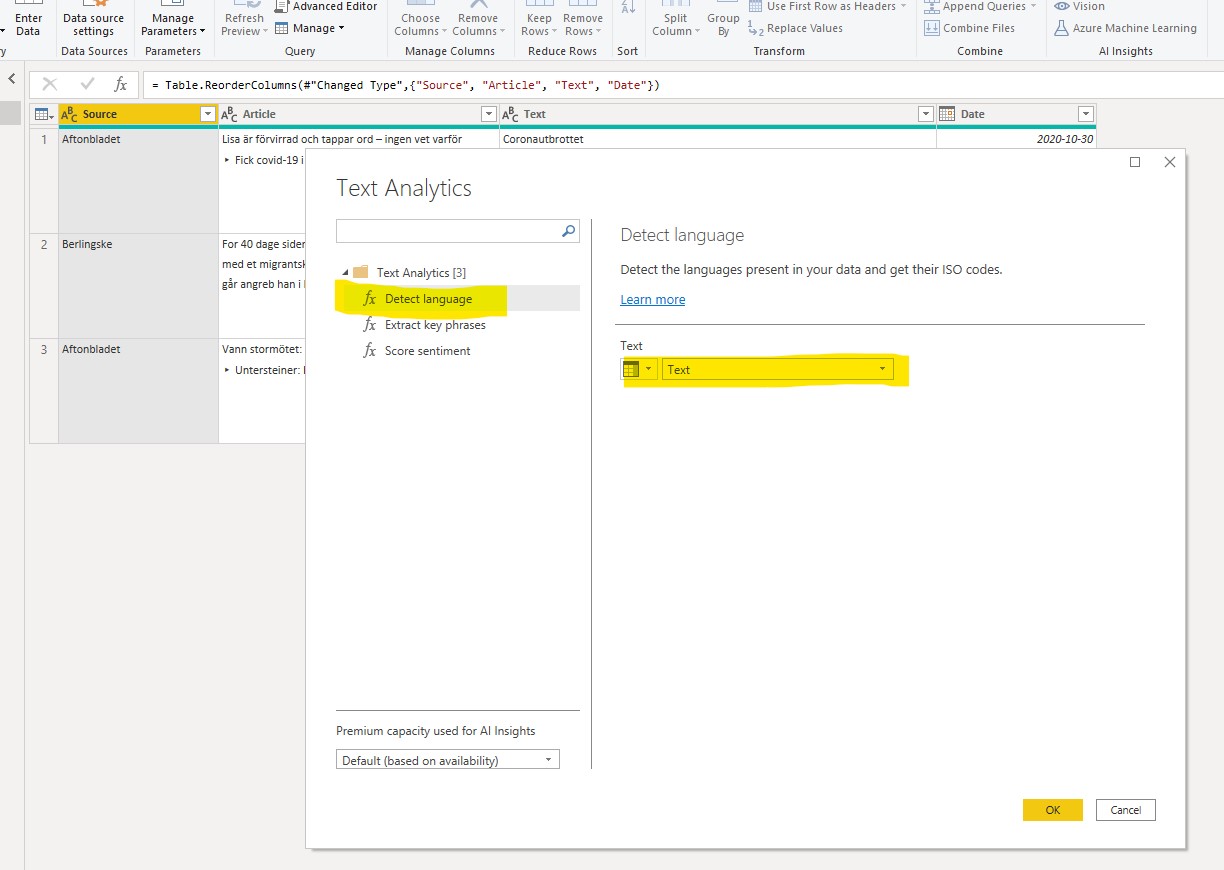
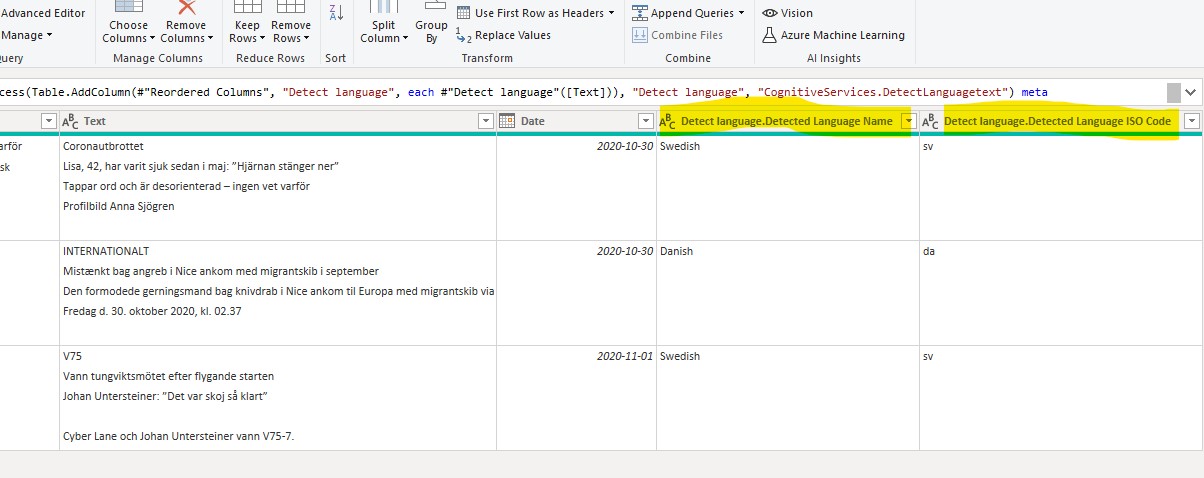
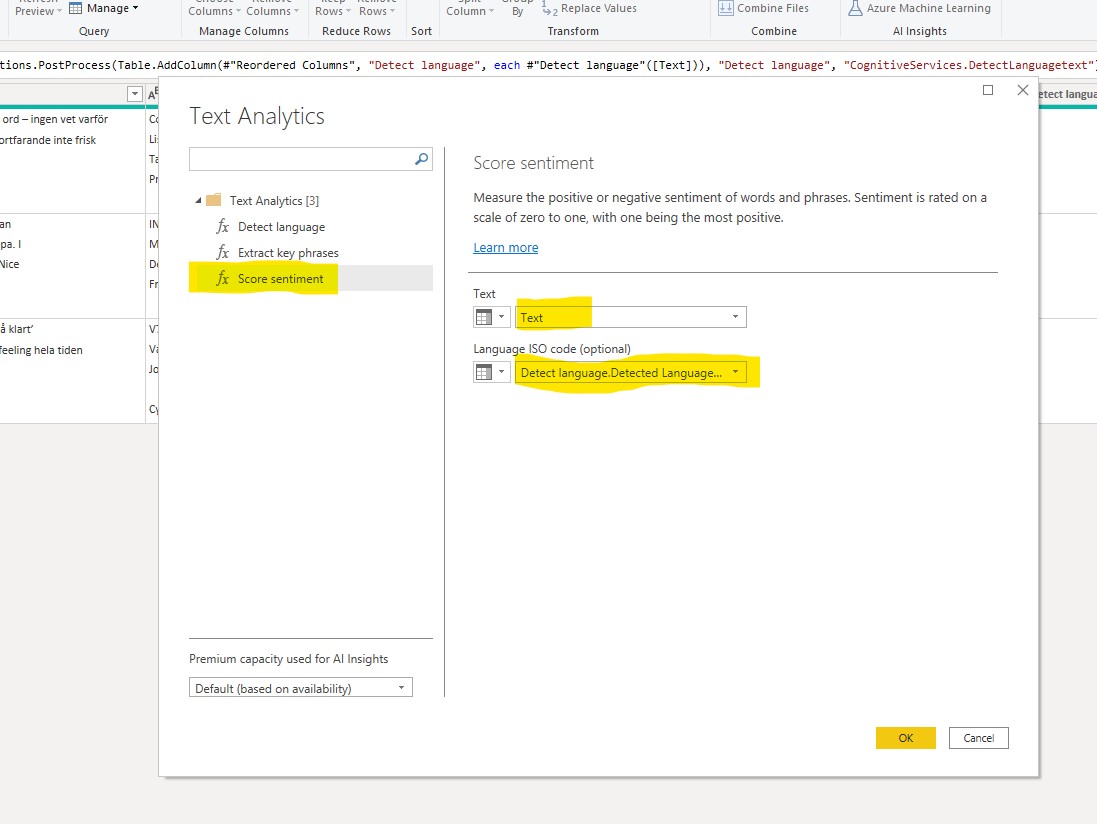
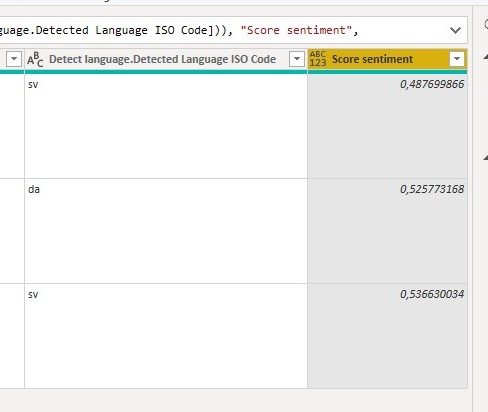
If you want some practical tips on how to transform your data to a star schema data model, I’d recommend the video below from Guy In a Cube. It also shows hands-on on how to use the Power Query functionality in Power BI which I always recommend to use.
Summary
- Smart data modeling will always make your dashboards faster and easier to work with. Moreover, if you are using multiple fact tables, dimension tables almost becomes a necessity.
- When building a star schema, you have fact and dimension tables. A fact table contains transaction-specific information, and a dimension table contains information common for a certain aspect of multiple transactions.
- Even though star schema modeling is best practice, your specific needs may require something else. However, you need to know the rules to break the rules.
- One can easily build a star schema data model from a single flat file using the Power Query Editor functionality in Power BI. A great way to improve efficiency of your dashboards by reducing data, and simplify development by having clearer tables.